A GLR parser builds multiple parse trees from an input token or event stream based on a grammar that may be ambiguous right up to the last input token. In practice this manifests itself in the following way.
As tokens are read, they advance the parser through a sequence of states, where each state represents for the top few items on the stack all possible partially-recognised rules that begin with that previously consumed sequence of tokens. Just before each token is consumed by the parser, the top few items on the stack are inspected to see if they match the set of tokens that appear to the right hand side of a grammar rule. If they do (and the next token to be consumed matches for the current state) that set of tokens is removed from the stack and replaced by the single non-terminal token that appears to the left of that grammar rule. The parser then jumps to a new state based on the uncovered top item on the stack just before the the single non-terminal replacement token was pushed. This replacement process is known as a reduction.
In a GLR parser, multiple stacks are actually implemented as a trellis structure. Where the sequence of input tokens have only a single interpretation according to the grammar rules, there will be a linked list simulating a single stack. When an input token would lead to two different interpretations, the stack branches into two, having now two stack tops that point back at the single node where the branch took place.
When two different paths through this stack-trellis are being reduced to the same non-terminal token at the left side of a grammar rule, and have the same uncovered top item on the stack just before pushing the single non-terminal replacement token, this constitutes a merging of two paths through the trellis into a single stack again. This is an opportunity to have the user of the parser choose which of those two paths represents the correct interpretation of the input token/event stream. Ultimately this will happen for every path through the grammar when we reduce the stacks generated from the whole input token stream to the top-level token of the grammar.
ParseLR allows you to specify in the input grammar file either some inline code or the name of a method of the parser class to be executed when this merge scenario is encountered.
Below is a modified grammar for the calculator example, modified so that the grammar deliberately has shift-reduce conflicts if treated as an LR(1) grammar, but therefore guaranteed to spawn multiple stacks if used as a grammar for a GLR parser. The shift reduce conflicts occur on the various expression : expression OP expression rules as indicated half way down the grammar.
options
{
namespace CalculatorDemo,
parserclass GLRCalculator
}
tokens
{
LPAREN, RPAREN, PLUS, MINUS, TIMES,
DIVIDE, POWER, NUMBER, PERIOD, EXPONENT
}
grammar(result)
{
result:
expression
{
// Result is a property of the GLRCalculator
// parser class, used to extract the result
// of the calculation after the parser has run.
Result = $$.ToString();
}
;
leafExpression:
optMinus number
{ $$ = (double)$0 * (double)$1; }
| optMinus LPAREN expression RPAREN
{ $$ = (double)$0 * (double)$2; }
;
optMinus:
MINUS
{ $$ = -1.0; }
|
{ $$ = 1.0; }
;
expression: // Shift reduce conflicts here
leafExpression
{ $$ = $0; }
| expression POWER expression
{ $$ = Math.Pow((double)$0, (double)$2); }
| expression TIMES expression
{ $$ = (double)$0 * (double)$2; }
| expression DIVIDE expression
{ $$ = (double)$0 / (double)$2; }
| expression PLUS expression
{ $$ = (double)$0 + (double)$2; }
| expression MINUS expression
{ $$ = (double)$0 - (double)$2; }
;
number:
NUMBER exponent
{
$$ = double.Parse($0.ToString())
* Math.Pow(10.0, (double)$1);
}
| NUMBER mantissa exponent
{
$$ = (double.Parse($0.ToString()) + (double)$1)
* Math.Pow(10.0, (double)$2);
}
| mantissa exponent
{ $$ = (double)$0 * Math.Pow(10.0, (double)$1); }
;
mantissa: PERIOD NUMBER
{
int digitCount = $1.ToString().Length;
double mantissa = double.Parse($1.ToString());
while(--digitCount >= 0)
mantissa *= 0.1;
$$ = mantissa;
}
;
exponent:
EXPONENT NUMBER
{ $$ = double.Parse($1.ToString()); }
| EXPONENT MINUS NUMBER
{ $$ = - double.Parse($2.ToString()); }
|
{ $$ = 0.0; }
;
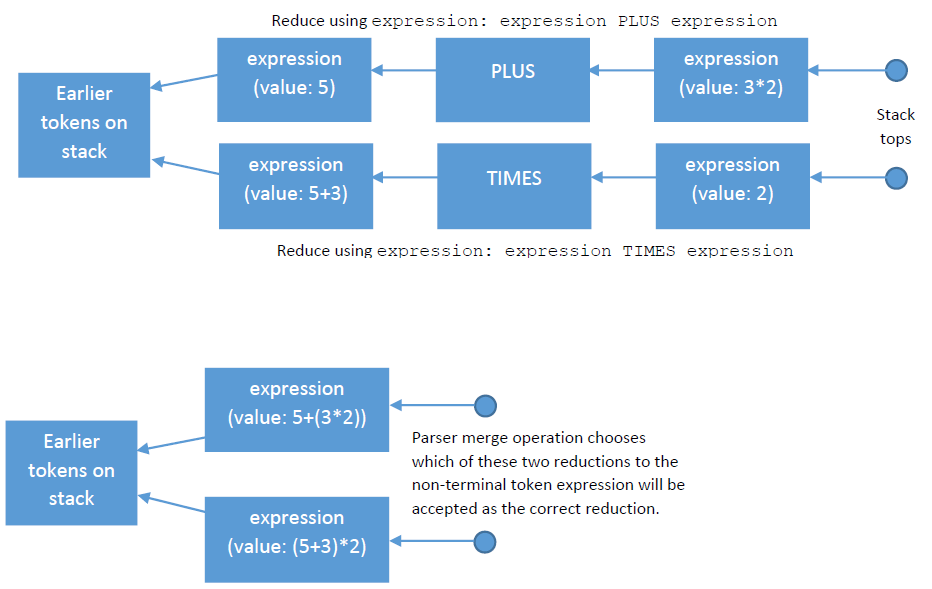
}Imagine that the expression 5 + 3 * 2 is parsed by this grammar. Because of the conflicts, two valid parse trees for this expression would be either (5 + 3) * 2 or 5 + (3 * 2). The GLR parser builds stacks that contain both these parses at the point that the whole thing reduces to a single expression non-terminal token. Given that the stacks are implemented as a trellis, the data structure before and after the reductions to expression non-terminals will look something like the following:
After reduction, we now have two identical stacks, each with the same common list of tokens lower down the stack, and each with an expression non-terminal token on the top. The only difference lies in how those two stack-top expressions were constructed. That information is held in the Value property of each of those two stack top expressions. Any input tokens that are consumed from this point onwards in the parse will have no effect on these two expression objects. Hence this is a point at which the parser could use other information to decide which of the two expression objects should survive, and which should be dropped as an incorrect parse of the input stream.
For each non-terminal token that can appear at the left of a set of grammar rules, it is possible to define a merge function that chooses between two reductions to that non-terminal when this happens. The merge function is passed the two token objects after reduction, and uses their values plus other surrounding context to decide which should survive, and which should be dropped, thereby reducing the number of surviving parses by one. Alternatively, the merge function might choose to let both parses survive, meaning that some later pair of reductions to a same token would have that token's merge function called to make the same decision.
Ultimately, the only surviving parses would be those that have a correct
grammar. These would all therefore reduce to the grammar entry symbol (as passed
in the parentheses after the grammar keyword). Hence a merge
function on the entry symbol would make the ultimate decision on which parse it
considers to be valid.
The next question to answer therefore, is how do we write merge functions for our GLR grammars?